What is re_data?
re_data is an open-source data reliability framework for modern data stack. 😊
Currently, re_data focuses on observing the dbt project (together with underlying data warehouse - Postgres, BigQuery, Snowflake, Redshift).
Live demo
Check out our live demo of what re_data can do for you! 😊
Alerts
re_data detects potential problems in your data like:
- anomalies (suspicious data patterns),
- failed dbt tests (new in 0.8.0 🎉),
- schema changes
and alerts you on Slack or Email and in re_data UI so that you can react, investigate and fix issues quickly. You can even setup more granual alerts for specific groups of people using re_data_owners setting.
Metrics
For detecting anomalies re_data uses metrics. You can compute predefined and custom metrics about your data. All metrics are stored in your database and accessible for you. re_data custom metrics are just dbt macros which you can add to your dbt project. Check out what base, extra metrics re_data has and how you can define your own metrics here:
Asserts
(new in 0.8.0 🎉)
re_data contains asserts library which enable you to test computed metrics using dbt tests. This additonal step allows you to make sure the data is correct and meets your expectations. Example tests in our asserts library:
Test history
re_data stores dbt tests history and let's you investigate test details like SQL which was run or failed rows for each runned test.
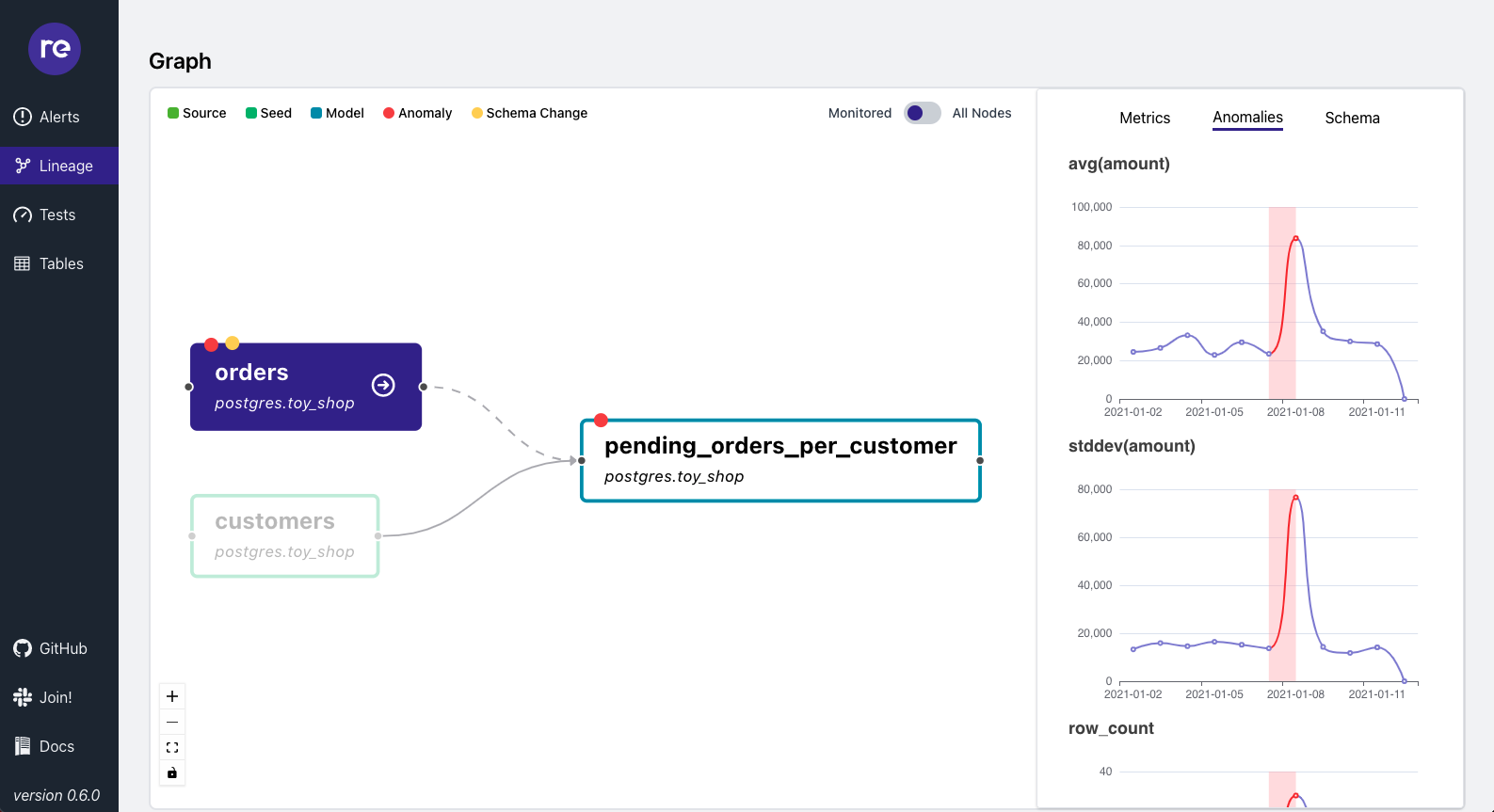
Lineage
re_data shows data lineage for your data warehouse. (This is imported from the dbt graph). You can navigate your data & investigate alerts & metrics related to each node in the graph.
Cleaning macros 🧹
re_data ships with a set of macros to save you time and pain of writing code for cleaning / normalizing / validating your data. Use them to make your project cleaner 😊. You can also use them as a base for your own metrics or data tests. Example macros in our data cleaning library include:
Getting started
re_data is very easy to add to existing dbt projects. Check out quickstart instructions and follow toy shop tutorial to see how you can generate re_data reliability data & UI for your data warehouse.
If you are not using dbt, re_data can still be a great option to start monitoring your existing tables. Check out installation for new users: new to dbt in this case.