What is re_data?
re_data is an open-source data reliability framework for modern data stack. 😊
Currently, re_data focuses on observing the dbt project (together with underlaying data warehouse - Postgres, BigQuery, Snowflake, Redshift).
Live demo
Check out our live demo of what re_data can do for you! 😊
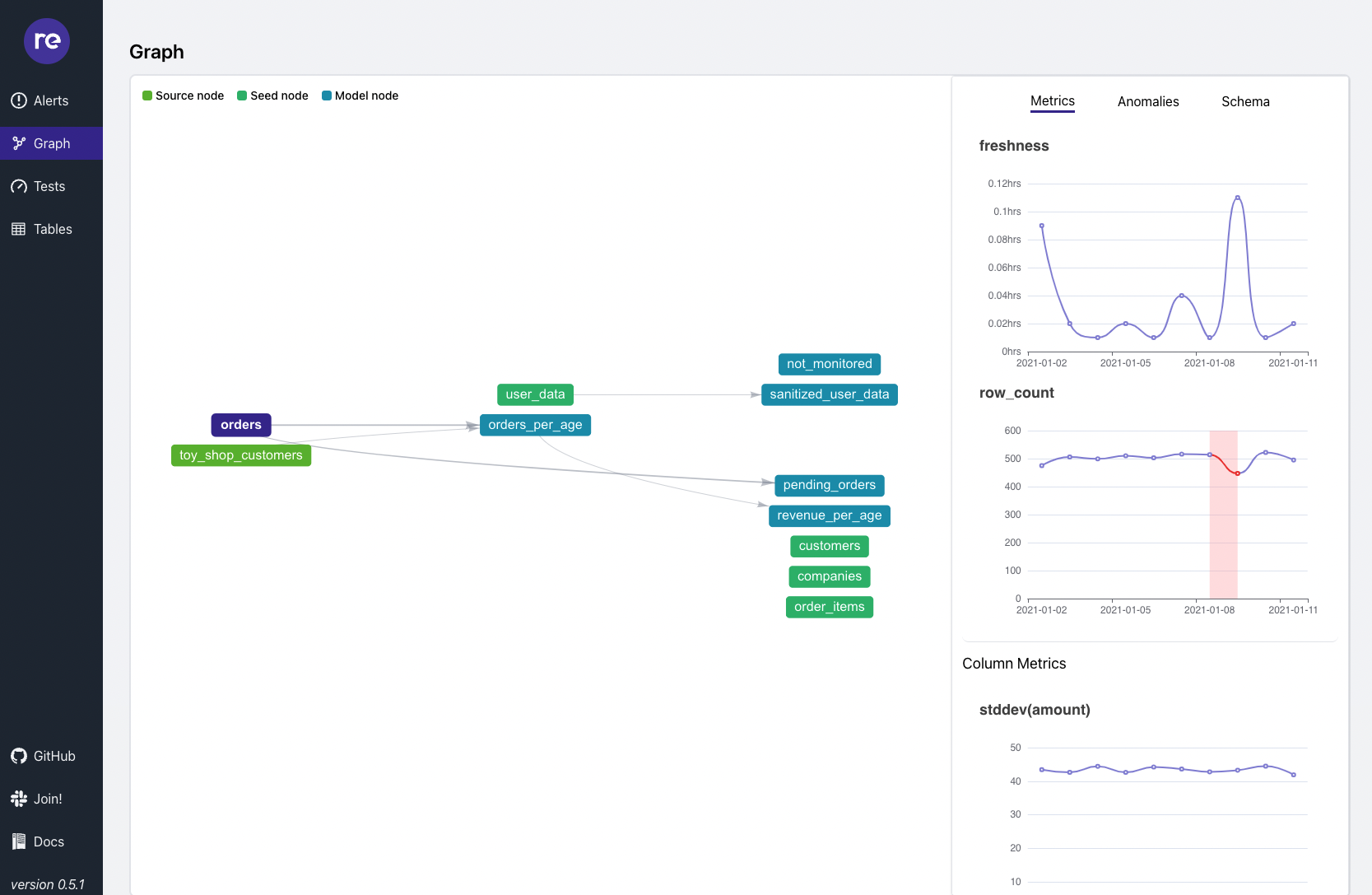
Features
Alerts#
Get information about suspicious data patterns & schema changes automatically. re_data detects trends in your data and creates alerts if something seems suspicious.
Metrics#
Monitor predefined and custom metrics about your data. All metrics are stored in your database and accessible for you. re_data custom metrics can be standard dbt macros which make it very easy to add them to your project.
Tests#
re_data stores dbt test history making it easier to inspect it. Apart from that re_data ships with a set of generic dbt tests which can be used to assert that metrics computed are meeting your assumptions.
Lineage#
re_data shows data lineage for your data warehouse. (This is imported from the dbt graph). You can navigate your data & investigate alerts & metrics related to each node in the graph.
Macros#
re_data ships with a set of macros to save you time and some pain of writing code for cleaning / normalizing / validating your data. Use them to make your project cleaner 😊. You can also use them as a base for your own metrics or data tests.
Notifications#
re_data sends notifications about suspicious data patterns, schema changes to your Slack so you can react quickly and fix the issues.
Getting started
re_data is very easy to add to existing dbt projects. Check out installation instructions and follow toy shop tutorial to see how you can generate re_data reliability data & UI for your data warehouse.
If you are not using dbt, re_data can still be a great option to start monitoring your existing tables. Check out installation for new users: new to dbt in this case.
Have more questions? Check out the rest of re_data docs, or ask as on Slack! 😊 (we are very responsive there)